


Supervision réseau
Back to glossaryQu’est-ce que la supervision réseau ?
Définition simple et rôle de la supervision réseau
La supervision réseau désigne l’ensemble des pratiques, outils et processus permettant de surveiller en continu l’état, les performances et la disponibilité d’un réseau informatique. Cela inclut les équipements, les connexions, les protocoles et les services au sein du réseau.
L’objectif principal est de détecter rapidement les anomalies, anticiper les défaillances et garantir une continuité de service optimale. Grâce à la supervision réseau, les équipes IT peuvent assurer un fonctionnement fluide de l’infrastructure, éviter les interruptions, et maintenir une expérience utilisateur sans accroc.
La supervision réseau consiste à surveiller en temps réel l’ensemble des composants d’un réseau informatique pour en garantir la disponibilité, la sécurité et la performance.
Qu’est-ce-que le monitoring réseau ?
Le monitoring réseau désigne l’observation en temps réel de l’état et des performances d’un réseau (trafic, latence, erreurs, etc.). Souvent utilisé comme synonyme de supervision réseau, il n’en est en réalité qu’un des composants. La supervision réseau inclut aussi la gestion des alertes, le reporting, l’analyse des causes et le suivi des SLA.
Supervision réseau vs supervision système : quelles différences ?
Bien que complémentaires, la supervision réseau et la supervision système ne ciblent pas les mêmes composants de l’infrastructure IT :
| Supervision réseau | Supervision Système |
| Contrôle les équipements réseau (switches, routeurs, firewalls…) et les flux entre machines |
Contrôle les serveurs, systèmes d’exploitation et ressources locales (CPU, mémoire, disque) |
| Vise la connectivité, la bande passante, la latence, les pannes de lien |
Vise les performances des machines et leurs disponibilités |
| Utilise souvent des protocoles comme SNMP ou ICMP |
Utilise des agents ou scripts locaux sur les serveurs |
En résumé, la supervision réseau se concentre sur la circulation des données, tandis que la supervision système s’intéresse à la capacité de traitement des machines.
Une plateforme de supervision complète comme Centreon ,permet de combiner les deux approches pour offrir une visibilité complète sur l’IT.
Les composants surveillés dans un réseau informatique (infrastructure, services, applications, etc.)
Une solution de supervision réseau efficace doit permettre de surveiller l’ensemble des composants critiques d’une infrastructure IT, qu’il s’agisse d’éléments physiques, virtuels ou applicatifs. Voici les principales catégories de composants surveillés :
1. Les équipements d’infrastructure réseau
Ce sont les éléments matériels qui assurent la connectivité entre les différents terminaux, serveurs et applications. Ils forment l’ossature du réseau d’entreprise.
- Commutateurs (ou switches) : ils relient les différents appareils d’un réseau local (LAN) et permettent de diriger intelligemment le trafic réseau. Leur supervision est essentielle pour détecter les ports en erreur, surveiller la bande passante ou anticiper une saturation.
- Routeurs : ils assurent la communication entre différents réseaux (ex. : site distant ↔ datacenter), et leur supervision permet de garantir la disponibilité des liaisons WAN et VPN.
- Pare-feux (firewalls) : ils protègent le réseau contre les accès non autorisés. Il est crucial de superviser leur état, leurs règles actives et les journaux de sécurité.
- Points d’accès Wi-Fi : ils offrent une connectivité sans fil aux utilisateurs. Leur supervision permet de suivre la qualité du signal, le nombre de connexions actives ou les canaux utilisés.
- Modems, passerelles, contrôleurs SD-WAN : ils gèrent les accès aux ressources distantes ou aux environnements cloud, et doivent être surveillés pour garantir la performance et la redondance.
La supervision des équipements réseau permet d’anticiper les coupures, de corriger rapidement les dysfonctionnements, et d’assurer une circulation optimale des données sur l’ensemble de l’infrastructure.
Centreon permet de superviser une large variété d’équipements réseau, y compris ceux issus d’environnements cloud managés comme Cisco Meraki, très utilisés pour la gestion centralisée de switches, routeurs et points d’accès Wi-Fi. Découvrez comment superviser efficacement votre infrastructure Cisco Meraki avec Centreon.
2. Les périphériques réseau
Dans une architecture réseau distribuée ou multisite, les périphériques connectés jouent un rôle souvent sous-estimé mais crucial dans l’expérience utilisateur finale. Ils doivent donc également être inclus dans la supervision :
- Imprimantes réseau : état, disponibilité, niveau de consommables
- Caméras IP : connectivité, flux vidéo, alimentation PoE
- Téléphones VoIP : qualité des appels, latence, disponibilité du service SIP
- Terminaux de point de vente (TPV) : essentiels dans le retail, ils doivent rester joignables en permanence
- Bornes Wi-Fi : nombre d’utilisateurs connectés, bande passante, canaux disponibles
En intégrant les périphériques à la supervision réseau, on améliore la qualité d’usage sur site et on réduit les sollicitations du support technique.
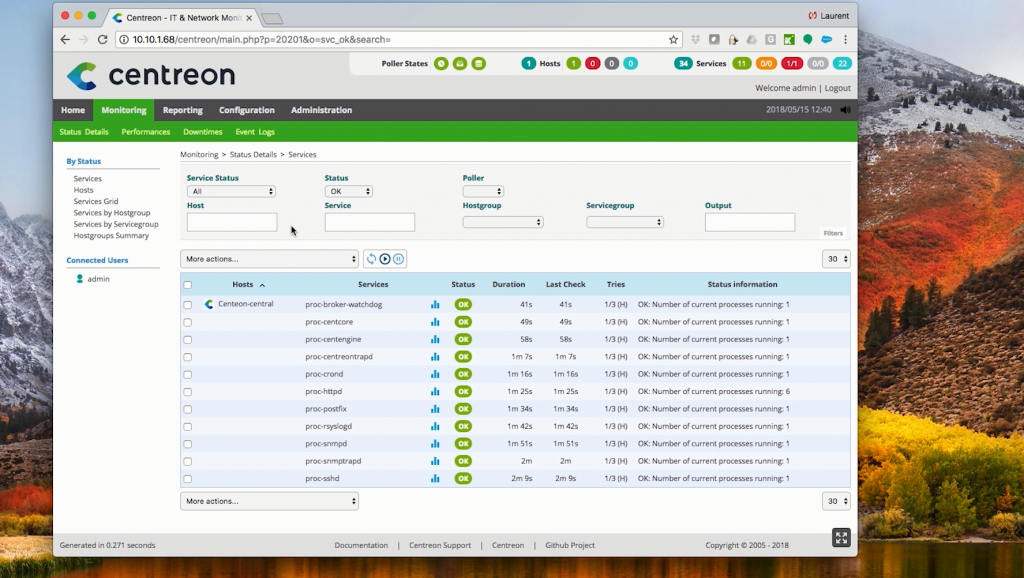
3. Les serveurs et machines hébergeant les services
Même si cela relève souvent de la supervision système, les serveurs doivent aussi être intégrés à la supervision réseau pour suivre :
- Leur accessibilité réseau
- Le temps de réponse des services hébergés
- L’état des interfaces réseau
- L’utilisation des ports ou protocoles critiques
Par exemple, un serveur de messagerie pourra être supervisé pour :
- Son état système (CPU, RAM, stockage)
- Sa connectivité réseau (ping, ports SMTP)
- Sa capacité à délivrer un service fiable (temps de réponse, disponibilité)
En croisant les données système et réseau, on obtient une vision complète du comportement des serveurs critiques.
4. Les services et protocoles réseaux
Il est essentiel de vérifier que les services clés du réseau fonctionnent correctement :
- DNS (résolution de noms de domaine)
- DHCP (attribution d’adresses IP)
- HTTP/HTTPS (accès web)
- SMTP/IMAP/POP3 (messagerie)
- FTP, SFTP (transfert de fichiers)
- VPN (accès distant)
La détection d’un service inactif ou lent permet d’agir avant que l’utilisateur ne le signale.
5. Les applications métier connectées
Une supervision informatique moderne ne se limite plus à la couche réseau : elle intègre aussi la supervision applicative, pour suivre :
- Le temps de réponse applicatif
- Le bon fonctionnement des API
- L’accessibilité des bases de données
- Les interdépendances entre applications et réseau
Cela permet de corréler les anomalies réseau à des impacts applicatifs (ex : lenteur d’un ERP due à un problème de routage).
6. Les flux et performances réseau
Enfin, une supervision avancée inclut l’analyse des flux de données et des indicateurs de performance réseau :
- Latence
- Jitter
- Perte de paquets
- Bande passante utilisée
- Taux d’erreurs sur les interfaces
Ces métriques permettent de diagnostiquer finement les problèmes et de garantir un réseau fluide.
A quoi sert la supervision réseau ?
Les objectifs principaux : disponibilité, sécurité, performance
La supervision réseau a pour vocation de répondre à trois objectifs stratégiques pour toute organisation connectée :
- Assurer la disponibilité des ressources
Surveiller en temps réel les équipements et les flux réseau permet de minimiser les interruptions de service et d’assurer une connectivité continue, 24h/24. - Renforcer la sécurité du réseau
En détectant des comportements anormaux (trafic inhabituel, équipements hors ligne, ports ouverts), la supervision contribue à identifier rapidement des menaces potentielles, comme des attaques DDoS ou des intrusions. - Optimiser les performances
Une supervision efficace permet de mesurer et analyser les performances réseau (latence, bande passante, goulots d’étranglement…) et d’améliorer la qualité de service, notamment sur les applications critiques.
En résumé : la supervision réseau permet d’anticiper les incidents, de réduire les temps d’intervention, et d’améliorer durablement l’efficacité opérationnelle.
Pourquoi la supervision réseau est-elle indispensable aujourd’hui ?
Avec l’évolution des infrastructures IT vers des modèles hybrides, multi-cloud et ultra-distribués, les réseaux sont devenus :
- Plus complexes
- Plus sollicités
- Plus critiques pour les activités métier
Dans ce contexte, le moindre incident réseau peut impacter directement la productivité, voire la réputation d’une entreprise. C’est pourquoi la supervision réseau n’est plus un luxe, mais une nécessité opérationnelle.
Une entreprise sans supervision réseau est comme un pilote sans tableau de bord.
Risques en cas d’absence de supervision réseau (incidents, pertes, indisponibilité)
Sans supervision active, les équipes IT opèrent à l’aveugle. Les risques sont nombreux :
- Pannes non détectées – arrêt brutal de services
- Incidents non anticipés – augmentation des interruptions
- Temps de résolution plus longs (MTTR) – perte de productivité
- Perte de données ou de clients – réputation compromise
- Risque de non-conformité réglementaire en cas d’incident majeur
En l’absence de visibilité, les problèmes sont souvent signalés par les utilisateurs finaux eux-mêmes, avec un impact direct sur la satisfaction client.
Supervision et expérience utilisateur : un lien direct
La qualité de l’expérience utilisateur dépend directement du bon fonctionnement des services numériques. Cela concerne :
- Un client qui attend une page e-commerce qui tarde à se charger
- Un collaborateur dont la messagerie est inaccessible
- Une caisse en magasin en panne à cause d’un routeur défectueux
Dans tous ces cas, une supervision réseau efficace permet de :
- Identifier les anomalies en amont
- Alerter immédiatement les équipes
- Corriger les dysfonctionnements avant que l’utilisateur ne soit impacté
Une infrastructure bien supervisée, c’est une expérience utilisateur fluide, continue, et conforme aux attentes.
Qui sont les utilisateurs de la supervision réseau ?
Administrateurs réseau et administrateurs systèmes
Les administrateurs réseau utilisent la supervision pour assurer la disponibilité, résoudre les incidents, et anticiper les dégradations sur les infrastructures techniques.
Ingénieurs DevOps / SRE
Ils l’intègrent dans des pipelines d’automatisation, pour monitorer l’infrastructure as code, les conteneurs ou les environnements cloud.
Responsables IT / DSI
Ils s’appuient sur les tableaux de bord stratégiques, les indicateurs de performance (KPI) et les rapports SLA pour piloter la qualité de service IT.
Équipes support et exploitation informatique
Elles reçoivent les alertes en cas de problème et peuvent intervenir proactivement, réduisant ainsi les sollicitations utilisateur.
Prestataires IT et MSP (Managed Services Providers)
Ils utilisent la supervision pour gérer à distance l’infrastructure de leurs clients et honorer leurs engagements contractuels (SLA).
Quels types de réseaux peut-on superviser ?
La supervision réseau ne se limite pas à une seule typologie d’infrastructure. Aujourd’hui, les environnements IT sont complexes, hétérogènes et souvent distribués, et la supervision doit s’adapter à cette réalité.
Une solution performante de supervision réseau — comme celle proposée par Centreon — doit donc être agnostique et capable de monitorer l’ensemble des architectures utilisées par les entreprises modernes.
Réseaux LAN, WAN, SD-WAN
- Réseau LAN (Local Area Network)
C’est le réseau local d’une organisation : postes de travail, imprimantes, serveurs, commutateurs… La supervision du LAN permet de contrôler la connectivité interne, la bande passante utilisée et de détecter rapidement les anomalies locales. - Réseau WAN (Wide Area Network)
Le WAN connecte plusieurs sites distants via un réseau étendu. Il est essentiel de superviser le WAN pour garantir une connexion fluide entre agences, sites industriels ou points de vente, surtout lorsqu’ils dépendent d’applications centrales. - Réseau SD-WAN (Software-Defined WAN)
Plus flexible et intelligent, le SD-WAN optimise les flux via une gestion logicielle du trafic réseau. La supervision SD-WAN est cruciale pour garder la maîtrise des chemins de données, détecter des basculements non souhaités, et valider la qualité de service (QoS) fournie par les opérateurs.
Réseaux hybrides, cloud, IoT
Les architectures modernes reposent sur des infrastructures hybrides, mêlant composants sur site (on-premise), hébergés dans le cloud, et parfois connectés à des objets intelligents (IoT).
- Réseaux hybrides
La supervision doit offrir une visibilité unifiée sur les environnements locaux et distants, même si les technologies varient d’un site à l’autre. - Cloud public, privé ou multi-cloud (AWS, Azure, GCP…)
Il est indispensable de monitorer les connexions entre les sites et le cloud, les temps de réponse des services hébergés, et les ressources cloud critiques (VMs, bases de données, APIs…). - IoT (Internet of Things)
Dans les environnements industriels, logistiques ou urbains, des milliers d’objets (capteurs, caméras, contrôleurs…) sont connectés. Une supervision adaptée permet de garantir la disponibilité et la sécurité de ces équipements souvent critiques.
Quels éléments peuvent être supervisés dans un réseau ?
Dans une approche moderne et complète de la supervision réseau, il ne suffit pas de surveiller uniquement les équipements physiques. Il faut également observer les flux, les services, la performance globale, et surtout les indicateurs clés (KPIs) permettant une lecture exploitable du bon fonctionnement du réseau.
Équipements réseau (switch, routeur, firewall, etc.)
Les équipements actifs du réseau constituent le socle de toute infrastructure. Leur supervision permet de garantir la disponibilité physique et logique de l’ensemble du système.
Voici les principaux composants surveillés :
- Switches (ou commutateurs en français) : détection de ports en erreur, surcharge, perte de connectivité
- Routeurs : suivi des interfaces WAN, des tables de routage, de la charge CPU
- Firewalls : surveillance des règles, journaux de sécurité, tentatives d’intrusion
- Points d’accès Wi-Fi : qualité du signal, nombre d’utilisateurs connectés
- Load balancers, proxys, modems, etc. : surveillance des performances et de la redondance
Ces équipements sont souvent interrogés via SNMP, ICMP, ou des agents pour remonter des données techniques précises.
Services et flux (HTTP, FTP, DNS, etc.)
La supervision réseau ne s’arrête pas au matériel : elle s’étend aux services réseau essentiels, qui doivent être accessibles et fonctionnels à tout moment.
Voici quelques exemples de services critiques à superviser :
- HTTP/HTTPS : accessibilité des sites web et portails d’entreprise
- DNS : bon fonctionnement de la résolution de noms de domaine
- DHCP : attribution correcte des adresses IP aux terminaux
- FTP/SFTP : vérification du transfert de fichiers
- SMTP/IMAP/POP : contrôle de la messagerie
- VPN : disponibilité et stabilité des connexions distantes
L’analyse des flux réseau (NetFlow, sFlow, IPFIX) permet également de visualiser quels protocoles ou services consomment le plus de bande passante.
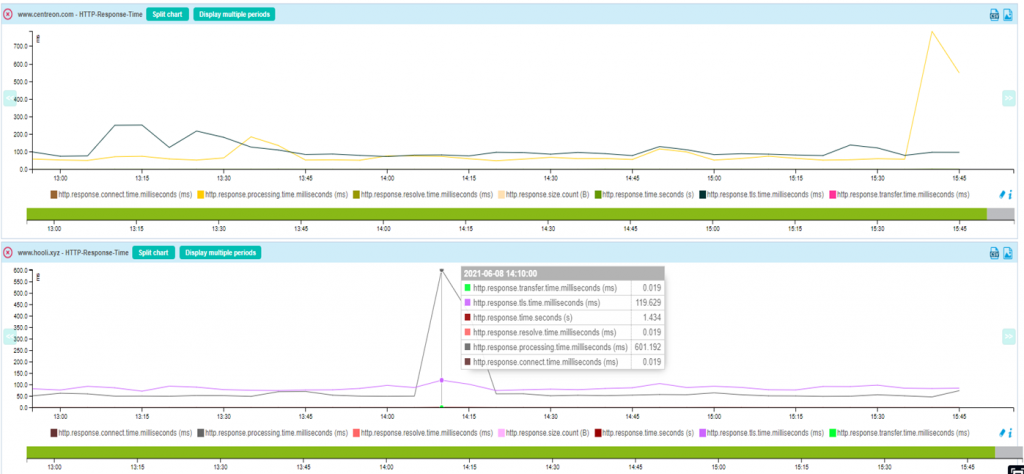
Disponibilité, bande passante, erreurs, latence, etc.
Au-delà des équipements et services, la supervision s’attache à mesurer des indicateurs de performance réseau fondamentaux pour diagnostiquer les lenteurs, les saturations ou les pertes de connectivité :
- Disponibilité : l’équipement ou le service répond-il ? Est-il accessible 24/7 ?
- Bande passante utilisée : niveau de trafic sur les interfaces, pics de charge
- Taux d’erreurs : erreurs CRC, paquets rejetés, collisions réseau
- Latence : délai entre l’envoi et la réception d’un paquet
- Jitter : variation du délai, important pour la VoIP ou la visioconférence
- Perte de paquets : indicateur d’une dégradation sérieuse de la qualité réseau
Ces métriques sont analysées en temps réel mais aussi historisées, pour identifier les tendances ou prévoir des saturations futures.
KPIs de supervision réseau
Les Key Performance Indicators (KPIs) permettent de synthétiser l’état de santé du réseau et de guider les décisions techniques ou managériales. Ils sont souvent présentés dans des dashboards personnalisés et peuvent être liés à des SLAs (Service Level Agreements).
Parmi les KPIs réseau les plus suivis :
- Taux de disponibilité (%) d’un lien, d’un site distant ou d’un équipement
- Temps moyen de réponse (d’un site, d’un serveur applicatif)
- Bande passante moyenne utilisée par site ou par utilisateur
- Nombre d’alarmes critiques sur une période donnée
- Temps moyen de résolution d’incidents (MTTR)
L’analyse de ces KPIs permet aux équipes IT de prioriser les actions correctives, d’automatiser les alertes, et d’améliorer la qualité de service globale.
Une supervision réseau efficace ne se limite pas à « surveiller des machines » : elle implique une vision fine de chaque couche, des équipements jusqu’aux flux, en passant par les services et les performances. Grâce aux KPIs, cette surveillance devient un véritable levier stratégique pour garantir la résilience et la fluidité des opérations IT.
Comment fonctionne un outil de supervision réseau ?
Un outil de supervision réseau agit comme une tour de contrôle des infrastructures IT. Il collecte, centralise et analyse en continu des données provenant de divers composants réseau, afin d’identifier les anomalies, déclencher des alertes, et aider les équipes IT à garder le contrôle sur l’état du système.
Principes techniques : agents, SNMP, ICMP, logs
Pour surveiller les équipements et les services réseau, les solutions de supervision s’appuient sur plusieurs protocoles et méthodes de collecte :
- SNMP (Simple Network Management Protocol)
Standard de communication utilisé pour interroger les équipements réseau (switches, routeurs, firewalls…) et récupérer des métriques (état des ports, bande passante, erreurs…). - ICMP (Internet Control Message Protocol)
Utilisé pour tester la disponibilité et le temps de réponse des hôtes via des commandes comme le ping. Utile pour détecter rapidement une perte de connectivité. - Agents logiciels
Petits programmes installés sur les serveurs ou équipements distants pour remonter des informations précises (CPU, mémoire, services actifs…). Certains outils fonctionnent également sans agent, via des protocoles standard. - Analyse de logs (syslog, journaux SNMP traps, etc.)
Les logs système, applicatifs ou réseau permettent de détecter des événements critiques (tentatives d’accès, échecs de services, redémarrages inattendus…).
Ces données sont ensuite corrélées et interprétées par la plateforme de supervision.
Architecture logique d’une solution type
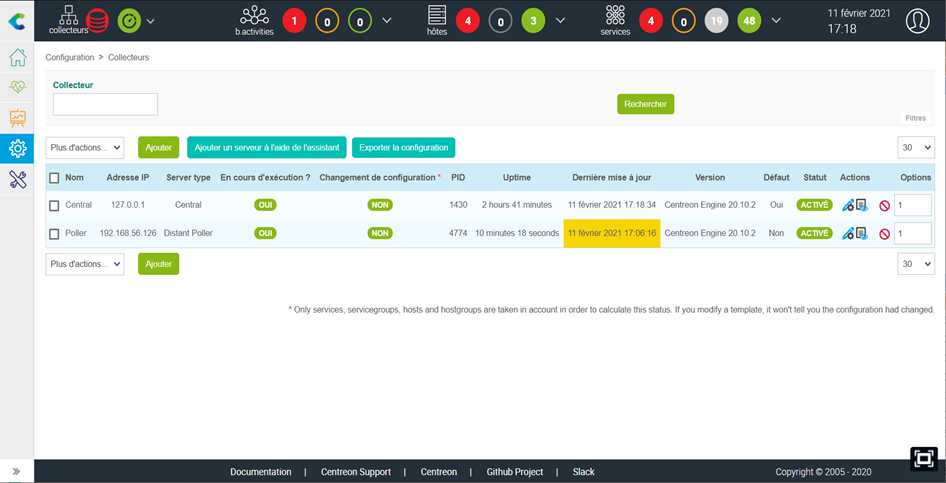
Une solution de supervision réseau repose généralement sur une architecture modulaire composée de plusieurs briques fonctionnelles :
- Collecteurs
Ils interagissent avec les équipements pour récupérer les données (via SNMP, ICMP, agents…). - Serveur de traitement
Il centralise les données, les analyse, déclenche les alertes, applique les règles de corrélation. - Base de données
Elle stocke les métriques collectées, les logs, les historiques d’événements pour permettre des analyses dans le temps. - Interface utilisateur (frontend)
Accessible via un navigateur web, elle permet aux équipes IT de consulter les états, recevoir des alertes, visualiser les dashboards et générer des rapports. - Moteur d’alerte
Il définit des seuils, des scénarios, et envoie des notifications en cas de dépassement (mail, SMS, API, webhook…).
Cette architecture peut être centralisée ou distribuée, selon la taille et la complexité du réseau supervisé.
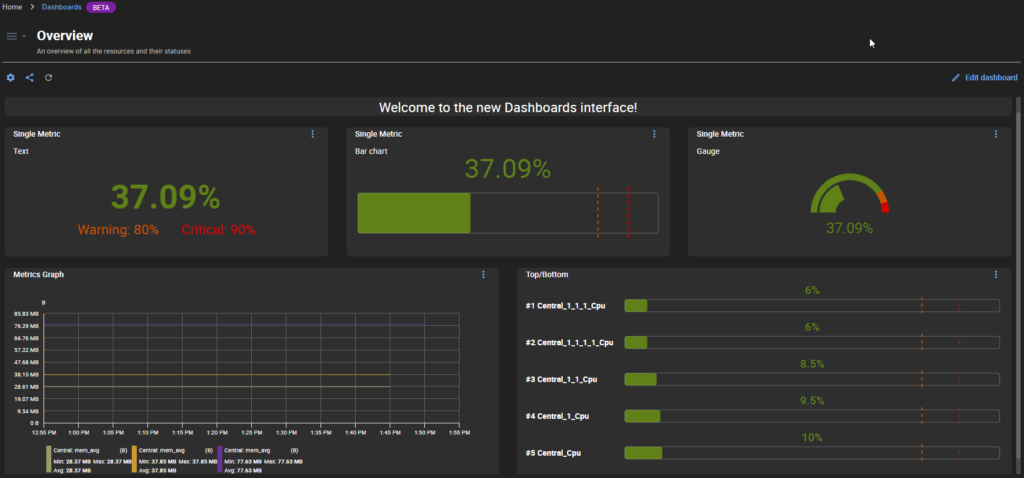
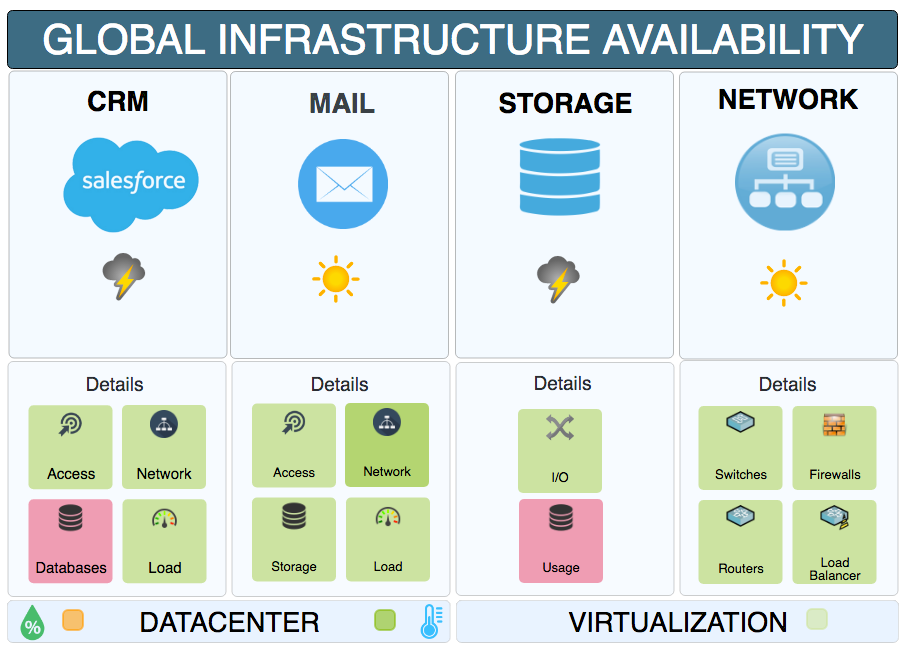
Centralisation et visualisation via dashboards
La valeur d’un outil de supervision réside aussi dans sa capacité à centraliser l’information et la rendre lisible et exploitable. C’est là qu’interviennent les dashboards.
Un bon tableau de bord permet de :
- Visualiser en temps réel l’état de tous les équipements
- Identifier immédiatement les zones critiques ou en alerte
- Suivre des KPIs personnalisés (temps de réponse, taux d’erreurs, bande passante…)
- Croiser des données réseau, système et applicatives
- Générer des rapports périodiques ou sur mesure
Ces dashboards sont adaptables aux différents profils utilisateurs (technique, métier, direction) et peuvent s’intégrer dans des portails ou des outils tiers via API.
Ce que doit proposer une solution de supervision réseau :
- Supervision temps réel des équipements réseau (SNMP, ICMP, etc.)
- Supervision des services critiques (HTTP, DNS, VPN, etc.)
- Visualisation graphique via des dashboards personnalisables
- Détection automatique des équipements et topologie réseau
- Système d’alertes paramétrable (seuils, escalades, canaux)
- Historique et analyse des performances sur le long terme
- Intégration avec ITSM, CMDB, outils de ticketing ou observabilité
- Compatibilité cloud, multi-sites, SD-WAN, IoT…
- Gestion multi-utilisateurs avec droits différenciés
- Open source ou API pour extension et personnalisation
Un outil de supervision réseau efficace doit allier robustesse technique, simplicité d’utilisation et ouverture vers l’écosystème IT, pour permettre aux équipes IT d’agir vite, de prévenir les incidents, et de piloter l’IT avec précision.
Quels sont les différents types de supervision réseau ?
La supervision réseau peut prendre différentes formes selon la méthodologie utilisée, la temporalité d’analyse, ou le mode de déploiement choisi. Pour bien comprendre ce que propose une solution de supervision, il est essentiel de connaître les différents types de supervision existants.
Supervision passive, active, réactive, prédictive
Supervision passive
La supervision passive repose sur la réception d’informations transmises par les équipements eux-mêmes, comme des traps SNMP ou des logs. Elle permet de réagir à un événement généré automatiquement (ex. : port tombé, seuil dépassé).
- Avantage : peu intrusive, rapide à mettre en œuvre
- Limite : dépendante de la capacité des équipements à remonter les alertes
Supervision active
La supervision active consiste à interroger régulièrement les équipements ou services, via des sondes (ping, SNMP, HTTP, etc.). Elle permet une analyse proactive de l’état du réseau.
- Avantage : donne une visibilité continue, même sans alerte native
- Limite : génère du trafic supplémentaire sur le réseau
Supervision réactive
Approche classique où l’outil détecte une anomalie et envoie une alerte pour intervention manuelle.
Elle repose sur des seuils prédéfinis.
- Exemple : si la bande passante dépasse 80 %, une alerte est générée.
Supervision prédictive
Grâce à l’analyse de données historiques et l’apprentissage machine, cette approche permet d’anticiper les dégradations ou incidents avant qu’ils ne surviennent.
- Exemple : le système prévoit qu’un lien réseau sera saturé dans 3 jours sur la base d’une tendance.
- Avantage : permet de passer d’un mode réactif à proactif, voire préventif
Supervision temps réel vs supervision historique
Supervision temps réel
Permettant de visualiser en direct l’état du réseau, de détecter immédiatement les anomalies (coupures, latence, pertes de paquets…) et de déclencher des alertes instantanées, elle est utilisée notamment pour la gestion d’infrastructures critiques (industrie, santé, e-commerce…).
Supervision historique
Consistant à enregistrer les données de supervision dans le temps pour effectuer des analyses, établir des rapports, et repérer des tendances d’évolution (pics de trafic, dégradation progressive…), elle est utile pour la planification capacitaire, la comptabilité réseau, ou l’amélioration des SLA.
Les deux approches sont complémentaires : le temps réel sert à l’action immédiate, l’historique à l’optimisation stratégique.
En résumé
| Type de supervision | Objectif principal |
|---|---|
| Passive | Réagir aux alertes émises automatiquement |
| Active | Mesurer en continu l’état du réseau |
| Réactive | Intervenir après détection d’un incident |
| Prédictive | Anticiper les pannes ou dégradations |
| Temps réel | Réagir immédiatement |
| Historique | Analyser et optimiser sur le long terme |
Exemples concrets de supervision réseau
La supervision réseau joue un rôle clé dans de nombreux secteurs. Qu’il s’agisse d’offrir une expérience client irréprochable, de garantir la continuité industrielle ou d’assurer un service public de qualité, les organisations s’appuient sur des solutions robustes et évolutives comme Centreon pour maintenir leur réseau sous contrôle.
Voici trois cas emblématiques dans des contextes très différents.
Retail : garantir une expérience client fluide
Dans le secteur du commerce, chaque seconde compte. Un terminal de paiement en panne, une étiquette électronique défaillante ou un site e-commerce indisponible peuvent immédiatement impacter l’expérience client et le chiffre d’affaires.
Cas client – Monoprix
Avec 861 magasins, 5 milliards d’euros de revenus et plus de 800 000 clients par jour, Monoprix doit garantir une disponibilité maximale de ses systèmes IT.
Défi : Superviser les équipements critiques de 725 points de vente (SD-WAN, balances, caisses, étiquettes électroniques, livraison à domicile…) pour assurer fluidité à l’encaissement et proactivité en cas d’incident.
Solution Centreon : une plateforme unique de supervision permettant à la DSI de centraliser les données de tous les sites et de réagir avant que l’incident n’impacte les opérations.
« La supervision Centreon est devenue un élément important voire critique de notre organisation IT et de notre performance, en particulier pour assurer une expérience client zéro défaut. »
Laurent Lelong, Chef du département Infrastructure et Réseau
Lire le témoignage Monoprix.
Industrie : superviser les lignes de production
Dans un environnement industriel, la moindre interruption réseau peut bloquer une ligne de production, générer des retards logistiques ou engendrer des pertes majeures. La supervision assure la disponibilité continue des flux IT et OT.
Cas client – Gerflor
Leader mondial des sols techniques, Gerflor supervise l’infrastructure IT de ses 47 sites internationaux grâce à Centreon.
Défi : Obtenir une vision centralisée et homogène sur l’ensemble du SI réparti dans de nombreux pays, sans compromettre la performance locale.
Solution Centreon : Déploiement d’un modèle de supervision multi-sites, avec des collecteurs locaux et une vision globale, permettant de détecter les anomalies sur les équipements industriels comme sur les applications critiques.
« J’ai pu mettre en place des choses que je n’aurais pas imaginées sans Centreon et qui profitent à toutes les équipes. Dans certaines filiales, nous sommes passés de quelques jours pour résoudre un incident à quelques minutes pour anticiper ce même incident et empêcher une indisponibilité du SI. Nous sommes beaucoup plus efficaces et proactifs dans la détection et la résolution d’incidents. »
Khalid Bounoun, Ingénieur Supervision et Sécurité
Lire le témoignage Gerflor.
Services publics : supervision d’un réseau distribué
Les institutions publiques (universités, administrations, établissements scientifiques) dépendent d’un réseau distribué, souvent à haute disponibilité, pour assurer leur mission de service.
Cas client – RNP (Réseau National de l’Éducation et de la Recherche du Brésil)
RNP connecte plus de 1 500 établissements d’enseignement supérieur et centres de recherche à travers le Brésil.
Défi : Superviser un réseau hautement distribué et stratégique, avec des exigences fortes en matière de sécurité et de disponibilité.
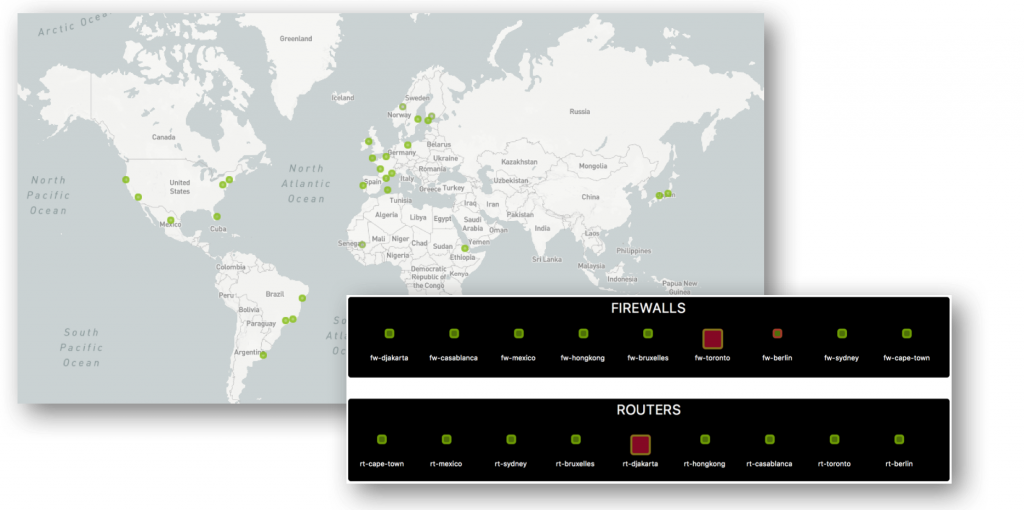
Solution Centreon : Plateforme de supervision avancée, intégrant des mécanismes de détection d’anomalies et une visualisation précise de la topologie réseau pour une résolution rapide des incidents.
« Centreon est un outil formidable car il répond à de nombreux besoins à la fois : de la réponse à des problèmes simples à la résolution de problèmes plus avancés, en passant par de nouveaux cas d’usage de la supervision informatique, par exemple, pour superviser des technologies réseaux innovantes pour l’éducation et la recherche. Dans tous les cas, Centreon permet de résoudre facilement les problèmes IT. »
Alisson Mesquita, Responsable du centre de supervision des réseaux
Lire le témoignage RNP.
En résumé
| Secteur | Objectif clé | Apport de la supervision Centreon |
|---|---|---|
| Retail | Fluidité en caisse, réactivité incident | Supervision centralisée des magasins |
| Industrie | Continuité de production | Visibilité multi-sites temps réel |
| Services publics | Haute disponibilité, sécurité réseau | Surveillance d’un réseau distribué stratégique |
Ces cas montrent que la supervision réseau n’est pas un luxe technique, mais un levier opérationnel et stratégique pour tous les secteurs.
Quelles fonctionnalités attendre d’un bon outil de supervision réseau ?
Un outil de supervision réseau efficace ne se limite pas à afficher l’état des équipements : il doit être capable de prévenir les pannes, d’alerter au bon moment et de s’intégrer dans l’écosystème global de l’entreprise. Voici les fonctionnalités essentielles à rechercher dans une solution professionnelle de supervision réseau :
Détection d’anomalies, alerting, reporting
Détection proactive des anomalies
Un bon outil doit permettre de détecter automatiquement les écarts par rapport au comportement attendu, que ce soit sur les équipements, les services ou les flux réseau. Cela inclut :
- Des seuils personnalisables (latence, bande passante, erreurs…)
- La reconnaissance des modèles de fonctionnement (normal, critique, dégradé)
- Des mécaniques d’auto-apprentissage (dans les solutions les plus avancées)
Système d’alerting intelligent
L’outil doit alerter la bonne personne, au bon moment, par le bon canal, sans générer de faux positifs. Les meilleures solutions proposent :
- Des alertes multicanal (email, SMS, API, webhook, Slack, Teams…)
- Des scénarios d’escalade (par gravité ou selon le moment de la journée)
- Des dépendances logiques pour éviter le bruit d’alerte
Reporting et tableaux de bord
Le reporting est indispensable pour :
- Fournir une vue synthétique des performances
- Documenter les incidents pour l’amélioration continue
- Produire des rapports SLA ou de disponibilité à destination de la DSI, des métiers ou des clients internes
Les rapports doivent être automatisables, personnalisables et exportables (PDF, CSV, etc.).
Intégration ITSM et Cloud
Connexion aux outils ITSM (Service Management)
Une supervision réseau efficace doit s’intégrer dans un écosystème IT plus large. Cela passe par des connecteurs natifs ou via API vers des outils comme :
- ServiceNow
- Jira Service Management
- GLPI
- BMC, Ivanti, EasyVista…
Cela permet d’automatiser la création de tickets incidents, d’associer les alertes à des services métiers et d’améliorer le temps moyen de résolution (MTTR).
Compatibilité avec les environnements Cloud
Aujourd’hui, le réseau s’étend bien au-delà du périmètre local. L’outil doit être capable de :
- Superviser les connexions vers des environnements AWS, Azure, GCP, etc.
- Intégrer des indicateurs issus du cloud (latence entre VPC, disponibilité d’une VM, santé d’une base cloud…)
- Corréler des données cloud avec l’infrastructure on-premise
Scalabilité, UX, automatisation
Scalabilité et performance
L’outil doit être capable de s’adapter à toutes les tailles d’organisation, de la PME à l’entreprise multi-sites, avec :
- Des collecteurs distribués
- Une base de données performante même sur plusieurs milliers d’hôtes
- Une architecture modulaire (avec extensions, plugins…)
Expérience utilisateur (UX) claire et intuitive
La supervision réseau doit être lisible et exploitable par tous : techniciens, ingénieurs, responsables IT.
L’interface doit proposer :
- Des dashboards dynamiques et interactifs
- Une navigation fluide avec filtres, tags, vues topologiques
- Un accès rapide aux informations clés, sans surcharge visuelle
Automatisation et orchestration
L’outil doit permettre de :
- Automatiser la découverte du réseau (scan SNMP, auto-découverte)
- Déployer des modèles de supervision standardisés
- Scripter des actions correctives ou des redémarrages
- Gérer des mises à jour ou des déploiements via API ou infrastructure as code
En résumé
Un bon outil de supervision réseau doit être :
| Critère | Exemples concrets |
|---|---|
| Proactif | Détection automatique des incidents et alertes intelligentes |
| Intégré | Connecté à l’écosystème ITSM, CMDB, Cloud |
| Scalable et robuste | Supporte les architectures complexes, multi-sites ou hybrides |
| Lisible | Dashboards ergonomiques et personnalisables |
| Automatisable | Découverte, configuration, actions correctives via API ou scripts |
Ces fonctionnalités permettent de réduire les risques, les coûts et les délais de réaction, tout en offrant plus de visibilité et de maîtrise sur le réseau.
Comment choisir un outil de supervision réseau ?
Pour sélectionner le bon outil de supervision réseau, plusieurs critères doivent être évalués pour faire un choix éclairé.
Critères clés (scalabilité, ouverture, ergonomie, coût, etc.)
- Scalabilité
L’outil doit pouvoir évoluer avec votre infrastructure, qu’elle soit en pleine croissance ou déjà étendue. Il doit gérer efficacement un nombre croissant d’équipements et de services sans compromettre les performances. - Ouverture et intégration
Une solution ouverte facilite l’intégration avec d’autres outils ITSM, bases de données, environnements cloud et applications tierces. Cela garantit une supervision unifiée et cohérente de l’ensemble de votre écosystème IT. - Ergonomie et expérience utilisateur (UX)
Une interface intuitive et conviviale permet aux équipes IT de configurer, surveiller et analyser les données de manière efficace, réduisant ainsi le temps de formation et augmentant la productivité. - Automatisation et auto-découverte
L’outil doit offrir des fonctionnalités d’auto-découverte des équipements et services, ainsi que des capacités d’automatisation pour simplifier les tâches répétitives et minimiser les erreurs humaines. - Coût total de possession (TCO)
Au-delà du coût initial, considérez les dépenses liées à la maintenance, aux mises à jour, au support et aux éventuelles extensions. Un TCO maîtrisé assure un meilleur retour sur investissement.
Questions à se poser avant de choisir
- Quels sont les besoins spécifiques de mon organisation ?
Identifiez les aspects critiques de votre infrastructure qui nécessitent une surveillance particulière. - L’outil est-il compatible avec nos technologies actuelles et futures ?
Assurez-vous que la solution s’intègre bien avec vos systèmes existants et qu’elle est adaptable aux évolutions technologiques à venir. - Quelle est la courbe d’apprentissage pour les équipes ?
Un outil complexe peut nécessiter une formation approfondie, impactant le temps de déploiement et l’efficacité initiale. - Quel niveau de support est proposé par l’éditeur ?
Un support réactif et compétent est essentiel pour résoudre rapidement les éventuels problèmes. - La solution offre-t-elle des fonctionnalités avancées telles que l’AIOps ou la supervision de l’expérience utilisateur ?
Ces fonctionnalités peuvent être déterminantes pour anticiper les incidents et améliorer la satisfaction des utilisateurs finaux.
Focus sur la solution Centreon
Centreon est une plateforme de supervision IT complète qui offre de nombreux avantages :
- Scalabilité et flexibilité
Centreon s’adapte aux infrastructures de toutes tailles, offrant une visibilité complète du cloud jusqu’à l’edge. Ses éditions variées permettent de choisir la version la plus adaptée à vos besoins. - Ouverture et intégrations étendues
Avec plus de 700 connecteurs prêts à l’emploi, Centreon s’intègre aisément avec divers environnements et technologies, facilitant une supervision unifiée. - Ergonomie et tableaux de bord personnalisables
L’interface intuitive de Centreon permet de créer des tableaux de bord sur mesure, offrant une visualisation claire des indicateurs de performance. - Automatisation et auto-découverte
Les fonctionnalités d’auto-découverte et d’automatisation de Centreon simplifient le déploiement et la maintenance de la supervision, réduisant ainsi le temps et les coûts opérationnels.
Essayez Centreon ! Centreon propose une édition gratuite et sans limite dans le temps, pour superviser jusqu’à 100 équipements, vous offrant une opportunité d’évaluer la solution sans engagement financier.
Comment mettre en place un projet de supervision réseau ?
Avant de vous lancer dans la mise en œuvre, découvrez comment la supervision réseau s’inscrit dans une stratégie globale de visibilité IT :
Centreon – Cas d’usage : supervision réseau
Mettre en place une supervision réseau efficace ne se résume pas à installer un outil. C’est un projet structurant pour les équipes IT, qui nécessite une vision claire, une mise en œuvre rigoureuse, et une adhésion organisationnelle.
Voici comment réussir cette démarche en trois temps.
Étapes clés : cadrage, déploiement, paramétrage
1. Cadrage fonctionnel et technique
- Identifiez les objectifs métier (disponibilité, performance, conformité, SLA…)
- Définissez les périmètres à superviser (équipements, flux, services critiques)
- Impliquez les parties prenantes : IT, support, sécurité, exploitation
- Choisissez les indicateurs clés (KPIs) et structurer les besoins en reporting
Astuce : créez une cartographie des composants réseau à superviser, classés par criticité.
2. Déploiement de la solution
- Installez l’outil de supervision réseau dans un environnement de test ou pré-prod
- Intégrez les connecteurs nécessaires (SNMP, cloud, ITSM, etc.)
- Mettez en place des collecteurs adaptés pour les environnements distribués
Astuce : privilégiez une approche modulaire et évolutive pour éviter l’effet tunnel.
3. Paramétrage et industrialisation
- Créez les modèles de supervision (modèles d’équipements, services, applications)
- Définissez les seuils d’alerte intelligents (warning, critique, dépendances)
- Configureez les dashboards personnalisés selon les profils utilisateurs (infra, métier, direction)
- Automatisez la découverte des nouveaux équipements si possible
Une fois ces étapes terminées, le projet entre en phase d’exploitation, avec une logique d’amélioration continue.
Bonnes pratiques de mise en œuvre
- Adoptez une démarche incrémentale : commencez par un périmètre restreint (ex. sites critiques), puis élargissez.
- Priorisez les composants critiques : supervisez d’abord ce qui a un impact direct sur l’expérience utilisateur ou la production.
- Impliquez les utilisateurs dès le départ pour comprendre leurs attentes en matière de visibilité, d’alertes et de reporting.
- Standardisez les configurations : utilisez des modèles pour simplifier les déploiements et la maintenance.
- Centralisez les données : regroupez la supervision réseau avec la supervision système et applicative pour une vision unifiée.
- Documentez la configuration pour assurer la pérennité du projet et faciliter la passation entre équipes.
- Supervisez la supervision : mettez en place des alertes sur l’état même de votre plateforme de monitoring.
Erreurs fréquentes à éviter
- Se lancer sans cartographie du réseau
Résultat : des équipements non supervisés, des angles morts, des alertes manquantes. - Configurer trop d’alertes dès le début
L’alerte fatigue arrive vite : les équipes ne savent plus quelles alertes sont vraiment critiques. - Sous-estimer le besoin d’accompagnement
Un outil mal configuré est un outil inefficace. Prévoir de la formation ou un accompagnement technique (interne ou éditeur). - Négliger les besoins métiers
Le reporting purement technique ne suffit pas. Pensez aussi aux indicateurs lisibles pour la DSI ou les directions opérationnelles. - Ne pas prévoir l’évolution
Le réseau évolue : nouveaux sites, cloud, SD-WAN, IoT… Votre supervision doit être scalable et régulièrement mise à jour.
En résumé
Mettre en place un projet de supervision réseau réussi, c’est :
- Bien cadrer.
- Déployer progressivement.
- Industrialiser intelligemment.
- Impliquer les équipes.
- Et éviter les pièges du « trop » ou du « pas assez ».
Les bonnes pratiques de la supervision réseau
Pour tirer toute la valeur d’un outil de supervision réseau, il existe des bonnes pratiques permettant d’exploiter au mieux les données collectées, d’éviter les faux positifs et de faciliter les prises de décision.
1. Définir des seuils pertinents
L’efficacité de votre supervision repose sur la définition intelligente des seuils d’alerte. Trop larges, ils laissent passer des incidents critiques. Trop stricts, ils déclenchent des alarmes inutiles.
Bonnes pratiques :
- Utilisez des seuils dynamiques ou adaptatifs basés sur l’analyse historique (plutôt que des valeurs fixes).
- Différenciez les seuils d’avertissement (warning) et les seuils critiques.
- Adaptez les seuils selon la criticté des équipements ou services (ex : un routeur principal vs un point d’accès Wi-Fi).
- Documentez les seuils pour maintenir une cohérence dans le temps.
Exemple : plutôt que d’alerter dès que l’utilisation CPU dépasse 70 %, il est possible de déclencher une alerte critique uniquement si ce seuil est maintenu pendant plus de 10 minutes.
2. Alerter sans sur-alerter
Trop d’alertes tuent l’alerte : elles fatiguent les équipes, masquent les vrais problèmes et ralentissent les prises de décision.
Bonnes pratiques :
- Regroupez les alertes liées (par dépendance ou proximité fonctionnelle).
- Créez des règles d’escalade pour impliquer les bonnes personnes au bon moment.
- Évitez les notifications inutiles la nuit ou sur des équipements non critiques (via des plages horaires ou des filtres).
- Utilisez des canaux différenciés selon la gravité (mail pour le warning, SMS ou ticket automatique pour le critique).
Astuce : Centreon propose des mécanismes de suppression d’alerte par dépendance logique (si un switch est coupé, pas besoin d’alerter sur tous les hôtes derrière).
3. Centraliser la supervision pour une meilleure visibilité
Aujourd’hui, les données réseau viennent de sources multiples : datacenters, sites distants, cloud, IoT, SD-WAN…
Bonnes pratiques :
- Utilisez une plateforme unifiée de supervision (infrastructure + services + applicatif).
- Déployez des collecteurs distribués pour agréger les données localement et les remonter de manière centralisée.
- Créez des vues par périmètre fonctionnel (réseau, applicatif, sécurité, etc.).
- Intégrez les données dans des dashboards métier pour les DSI ou responsables de production.
4. Intégrer la supervision réseau avec d’autres outils ITSM ou observabilité
La supervision réseau ne doit pas fonctionner en vase clos. Pour maximiser sa valeur, elle doit s’intégrer avec l’ensemble de la chaîne de gestion des services IT.
Bonnes pratiques :
- Connectez la supervision aux outils ITSM (ServiceNow, Jira Service Management, GLPI…) pour créer des tickets automatiquement.
- Partagez les événements critiques avec les outils de logs ou d’observabilité (Elastic, Grafana, Prometheus, etc.).
- Utilisez des API pour envoyer les données vers des plateformes de reporting, de sécurité ou de gestion des capacités.
- Favorisez des solutions compatibles CMDB et SLA tracking.
Découvrez Centreon, à travers nos démos intéractives.
En résumé
| Bonne pratique | Objectif |
|---|---|
| Définir des seuils pertinents | Déclencher les alertes au bon moment |
| Éviter le sur-alerting | Garder les équipes concentrées sur l’essentiel |
| Centraliser la supervision | Avoir une vision claire, consolidée, exploitable |
| Intégrer avec l’ITSM & observabilité | Fluidifier la chaîne de gestion des incidents |
FAQ – Tout savoir sur la supervision réseau
Quel est le rôle d’un administrateur réseau ?
Un administrateur réseau est responsable de la mise en place, du bon fonctionnement et de la sécurité des réseaux informatiques. Il s’assure que les utilisateurs peuvent accéder aux ressources internes et externes (applications, Internet, imprimantes, serveurs…) de manière fluide, stable et sécurisée.
Il utilise la supervision réseau pour :
- Surveiller les équipements et les flux de données.
- Détecter les incidents (pannes, saturations, pertes de connectivité…).
- Optimiser les performances.
- Assurer une haute disponibilité du réseau.
La supervision est donc au cœur du métier d’administrateur réseau.
Est-ce important de superviser un commutateur réseau (switch) ?
La supervision des commutateurs réseau (ou switches) est essentielle. Ces équipements assurent la circulation des données au sein du réseau local (LAN). Une panne de switch peut provoquer une perte de connectivité, des ralentissements ou des interruptions de service.
Cela permet de :
- Surveiller l’état des ports, la bande passante, les erreurs ou collisions.
- Identifier les saturations ou les équipements défectueux.
- Agir rapidement avant qu’un incident n’impacte les utilisateurs.
Superviser ses commutateurs, c’est garantir la fluidité, la performance et la stabilité du réseau.
Peut-on superviser un réseau sans agent ?
Il est tout à fait possible de superviser un réseau sans agent. Les outils modernes utilisent des protocoles standards comme SNMP ou ICMP pour interroger les équipements à distance, sans nécessiter d’installation locale.
La supervision sans agent est idéale pour les environnements hétérogènes ou sensibles, car elle permet une mise en œuvre rapide et non intrusive. Cependant, pour des analyses plus fines (ex. : processus applicatifs, logs système), un mode agent peut être recommandé en complément.
Qu’est-ce qu’un outil de monitoring réseau open source ?
Un outil de monitoring réseau open source est une solution gratuite ou librement accessible, sans coût de licence.
Quels sont les logiciels de supervision réseau ?
Parmi les logiciels de supervision réseau, on peut trouver :
- Centreon.
- Zabbix.
- PRTG Network Monitor.
- Nagios.
- SolarWinds.
Qu’est-ce que la supervision des serveurs ?
La supervision des serveurs consiste à surveiller l’état et les performances des machines physiques ou virtuelles pour anticiper les pannes, d’optimiser les performances et de réduire les interruptions. Elle couvre des éléments comme :
- La charge CPU.
- La mémoire utilisée.
- L’espace disque disponible.
- Le statut des processus et des services.
Quels sont les trois types de supervision ?
Il y a trois grands types de supervision :
- Supervision réactive : détecte un incident après qu’il s’est produit.
- Supervision proactive : anticipe les incidents grâce à des seuils et à l’analyse de comportement.
- Supervision prédictive : utilise l’analyse de tendances ou des algorithmes d’intelligence artificielle (AIOps) pour prévoir les problèmes avant qu’ils ne surviennent.
Ces trois approches peuvent être combinées dans une stratégie de supervision efficace et moderne.
Glossaire des termes liés à la supervision réseau
Pour bien comprendre le fonctionnement de la supervision réseau et interpréter les indicateurs fournis par un outil comme Centreon, il est essentiel de maîtriser quelques notions clés. Voici les termes les plus utilisés.
Monitoring réseau
Le monitoring réseau permet de détecter les anomalies, de générer des alertes et de produire des rapports sur l’état de santé du réseau.
SNMP (Simple Network Management Protocol)
Protocole de communication standardisé utilisé pour collecter des informations à distance sur les équipements réseau. Il permet une supervision sans agent.
PING
Commande réseau basée sur le protocole ICMP, utilisée pour tester la disponibilité d’un hôte sur un réseau. Elle mesure également le temps de réponse (latence). Très utilisée en supervision active.
Latence
Délai (en millisecondes) entre l’envoi d’un paquet et sa réception. Une latence élevée peut entraîner des lenteurs applicatives, surtout sur les services temps réel (VoIP, visioconférence…).
Topologie réseau
Représentation graphique ou logique de la structure d’un réseau, incluant les liens entre les équipements. Elle permet de visualiser cette topologie en temps réel pour identifier rapidement les zones critiques.
Trap SNMP
Message d’alerte envoyé automatiquement par un équipement vers l’outil de supervision, sans qu’il ait besoin d’interroger l’équipement. Utile dans les stratégies de supervision passive.
MTTR (Mean Time To Repair)
Temps moyen nécessaire pour résoudre un incident réseau. C’est un KPI critique pour évaluer l’efficacité du support et des outils de supervision.
Jitter
Variation de la latence dans le temps. Un jitter instable peut impacter la qualité des flux temps réel (téléphonie IP, streaming, etc.).
SLA (Service Level Agreement)
Engagement de niveau de service entre un fournisseur et un client (interne ou externe). La mesure du respect des SLA, porte notamment sur la disponibilité et la performance.
Passez à la pratique et évaluez Centreon :
Vous êtes responsable de la supervision et vous souhaitez valider l’adéquation fonctionnelle de Centreon avec votre besoin de superivsion ?
Le mieux c’est encore d’évaluer et tester Centreon :
- Explorez les connecteurs, l’interface et les dashboards de Centreon avec notre démo intéractive.
- Echangez directement avec un expert en nous contactant.
- Testez Centreon dans votre environnement : avec Centreon IT Edition 100, vous pouvez superviser jusqu’à 100 équipements gratuitement et sans limite de temps !
Pages linked on this





























































































































































































































































































































Découvrez comment Centreon va transformer votre business
Restez informés sur notre actualité