



We recently attended the 2018 Monitorama Conference in Portland, Oregon, and we thought you might like us to share some of the most meaningful insights we took back home with us. You can expect us to come back with more detailed posts on some of them – because we like to keep you on top of things.
Hot Topics in Portland
A tech city in its own right, Portland is often called Silicon Forest. Now that we’ve positioned this nugget of trivia, let’s move on to the key learnings we drew from the talks and discussions facilitated by industry experts and community leaders on the newest approaches in monitoring and observability.
These are the topics that will most likely be on your mind in the coming months:
- Alert fatigue
- Decision fatigue
- Context matters
- True Meaning of observability
- Symptoms vs causes of service degradation
1- Alert Fatigue
A pain point for ages in the IT world, alert fatigue is the poster boy for many of our ailments: from negligence to inefficiency right down to bad decisions and avoidable downtime, not mentioning the losses in productivity and revenue for our companies or clients.

Source: Aditya Mukerjee, Monitorama 2018 , “Warning: This Talk Contains Content Known to the State of California to Reduce Alert Fatigue”
In his talk, Aditya Mukerjee defined Alert Fatigue as a moment, “When the frequency or severity of alerts causes the responder either to ignore important alerts or make mistakes more frequently.”
And there’s not just alert fatigue you have to worry about.
2- Decision Fatigue
Abundance of data is nice, but it’s not necessarily a marker for smarter decision-making. Being confronted to a deluge of facts and metrics when an urgent decision needs to be made feels like trying to host a picnic below a bee nest. Decision fatigue is an aftermath of alert fatigue, which happens, according to Aditya Mukerjee, “When the frequency or complexity of decisions points causes a person to avoid decision or make mistakes more frequently.”

Source: Aditya Mukerjee, Monitorama 2018 , “Warning: This Talk Contains Content Known to the State of California to Reduce Alert Fatigue”
You want an example? Here’s one taken from his talk:

Source: Aditya Mukerjee, Monitorama 2018 , “Warning: This Talk Contains Content Known to the State of California to Reduce Alert Fatigue”
Visitors to this Disneyland resort are faced with this alert – which provides no context to help make the right decision as to what would constitute a proper course of action. Imagine parents fleeing the place without even asking for a refund, crying kids in tow, and you have a pretty good illustration of what happens when you combine urgency to make a decision with poor or insufficient context for the information that is supposed to assist you.
In his talk, Aditya Mukerjee referred to the STAT acronym, which has long been used by emergency services, to define the attributes of alerts that are attention worthy to SRE teams:
- Supported: someone has to own the monitoring linked to the alert, knows the impact and should be able to modify it if needed.
- Trustworthy: you’re only notified when there is a problem, never when there is not, and you have enough information to diagnose the problem.
- Actionable: alert is interactive, it can be drilled down, and ownership to take the action (i.e. who calls 911!) as clearly been established.
- Triaged: urgency & priority needs are visible and can be re-evaluated if they’re not consistent
The friendly cousin of both alert and decision fatigue is Context.
3- Context Matters
So there you go, context matters – and more than ever, as our work – and our IT infrastructure – keep getting more complex. Although context sounds like a fuzzy concept, one that may be associated with intuition (“hold it, something’s off here!”) – context is really about putting your data house in order so that you can keep track of where things are, in a split second and without even needing to look too deeply into it. Most people aren’t neat freaks, so the equivalent of getting organized in the realm of IT monitoring is context automation. In his talk, Andy Domeier provides a great starting point to improve your practices.
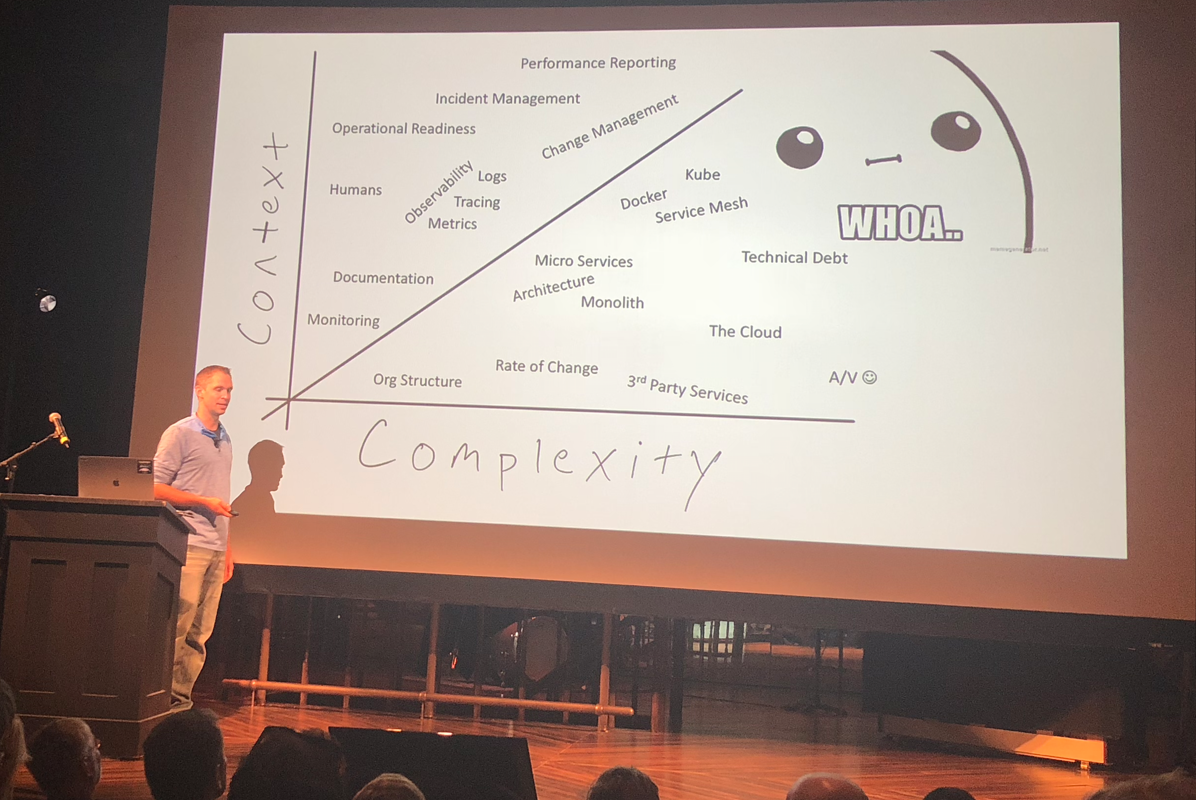
Source: Andy Domeier, Monitorama, Portland 2018, “Automate your Context”
To stay within the neatness analogy, you don’t want to rummage in the darkest corners of your fridge each time you’ve got a craving for a hamburger. You want all the necessary condiments neatly aligned and visible on the fridge door shelf, patiently waiting to serve in the next “hamburger” situation.
We may not have been aware up to now, but it appears our work is a lot like fixing hamburgers on the fly, in a kitchen that’s taking orders from picky people all over the world. Data needs to be grouped by concepts and be easy to visualize (and analyzed), according to their relevant context. And because things can quickly get messy, there are advanced tools that let you work with multilayers of visualization, like Vizceral, which was born at Netflix and is still used today to understand the state of their complex microservice architecture, in any part of the world, at a glance, when performing a traffic failover.
4- Observability
We liked this presentation at Monitorama because it contributes to defining a common (and actionable!) vision of what is meant exactly by “observability”. For many observability is a rebrand of “monitoring” like Ops was rebranded DevOps. Monitoring is about getting the overall health of a system where observability is about getting highly detailed information concerning the behavior of the system (logs, traces etc…) for debugging purposes. So yes observability is monitoring, but monitoring taking place within a continuum of steps that must be deployed to make a system “observable.” Here’s how the Observatory Engineering team at Twitter explained it for the first time in this article.

Source: Yan Cui, Monitorama 2018, Portland, “The present and future of Serverless observability“
Making complex, distributed IT systems observable supports troubleshooting and debugging, allowing to see what’s there, get meaningful, context-rich alerts, have a sense of what’s happening or what is about to happen, and garner intel from the analytic data.

Source: Yan Cui, Monitorama 2018, Portland, “The present and future of Serverless observability“
If you want to learn more about observability and monitoring, you should have a look at this article. Yan Cui then focused its talk on its main subject : Serverless observability.
Serverless systems, such as AWS Lambda, pose additional observability challenges. Actually, these are the environments that are forcing us to acquire new practices and develop or learn to use new tools. Yan Cui talked about the monitoring problems you face when you use serverless concepts:
- Impossibility to install agent/daemons
- No background processing
- Higher concurrency to telemetry system
- Asynchronous invocations
We like the series of articles authored by Yan Cui.
5- Symptoms vs causes
We loved hearing about the symptoms approach which places the focus on user experience and SLO rather than on the potential causes of service degradation. In this paradigm, alerts are based on what the user is getting (aka symptom-based alerting). As it’s explained in the Google SRE Book:
“Your monitoring system should address two questions: what’s broken, and why? The “what’s broken” indicates the symptom; the “why” indicates a (possibly intermediate) cause.“What” versus “why” is one of the most important distinctions in writing good monitoring with maximum signal and minimum noise.”
Why is it that focusing on the user perspective and symptoms is the best monitoring strategy? It turns out that with the exponential growth of our systems, user experience is the most stable, scalable ground to work from. Users will not change – whereas with an evolving system, you keep having to write more and more rules to keep things under control.
By clearly defining SLO and putting them in the heart of your monitoring system and alerts, you will get paged only when there is a real risk on the budget/customers’ experience and not when things that don’t really matter are broken. Being symptom-oriented is a good strategy to tackle alert and decision fatigue problems.
We will be at Monitorama Amsterdam on September 4-5, 2018 and will make sure to keep you posted on the interesting topics discussed over there.
Want to see how Centreon helps with the most pressing issues of IT monitoring? Contact us.
Keep in touch with us to stay abreast of the new developments that are reshaping IT monitoring.
Share











