



Nous avons récemment participé à la conférence 2018 Monitorama à Portland (Oregon) au cours de laquelle nous avons assisté à des conférences particulièrement intéressantes sur les derniers sujets d’actualité en matière de supervision. Nous avons sélectionné pour vous 5 pistes de réflexion très pertinentes dont nous vous livrons une première approche dans cet article. Nous approfondirons ces sujets rapidement dans de prochains articles.
Cet article est une adaptation française de l’article 5 Pieces of Wisdom We Took Home from Monitorama 2018. Nous avons traduits certains concepts du mieux que nous pouvons car ces concepts sont tellement nouveaux qu’ils n’ont encore jamais, ou très rarement, été traduits. N’hésitez pas à vous référer à l’article en version anglaise.
Quoi de neuf à Portland ?
Plantons le décor : Portland a tout d’une ville technologique, ce qui lui a d’ailleurs valu le surnom de « Silicon Forest ». C’est dans cet environnement propice qu’ont eu lieu de nombreuses prises de paroles et débats entre experts et leaders communautaires sur les nouvelles approches en matière de supervision informatique et d’observabilité.
Parmi les derniers sujets évoqués, 5 ont particulièrement retenu notre attention car ils seront probablement au cœur de vos préoccupations dans les mois à venir :
- La prise en compte de l’alerte fatigue
- L’épuisement décisionnel
- L’importance du contexte
- La vraie définition de l’observabilité
- L’approche centrée sur les symptômes versus celle centrée sur les causes
1 – L’alerte fatigue ou quand trop d’alertes tuent l’alerte
Sujet sensible depuis toujours dans le monde de l’IT, le déluge d’alerte (ou Alerte Fatigue) est en tête sur la liste des problématiques rencontrées par les équipes de supervision. De la simple négligence à une inefficacité chronique conduisant à une mauvaise prise de décision et à des indisponibilités qui auraient pu être évitées, l’alerte fatigue est un phénomène difficile à adresser et occasionne des pertes de productivité et de chiffre d’affaires pour les entreprises comme pour les clients.

Source: Aditya Mukerjee, Monitorama 2018 « Warning: This Talk Contains Content Known to the State of California to Reduce Alert Fatigue »
Au cours de sa conférence, Aditya Mukerjee a défini l’alerte fatigue comme « le moment où la fréquence ou la gravité des alertes est telle que la personne concernée ignore les alertes importantes ou commet des erreurs plus fréquemment ».
Pourtant, il n’y a pas que de ce type de surmenage dont vous devez vous méfier…
2 – A propos de la fatigue décisionnelle (decision fatigue)
Disposer de nombreuses données est très rassurant mais ne signifie pas que les décisions qui seront prises à partir de cette abondance de données seront les plus pertinentes. En effet, être confronté à un déluge d’informations et de métriques quand il faut prendre une décision dans l’urgence n’est pas efficace… La fatigue décisionnelle (ou decision fatigue) est une des conséquences du déluge d’alertes, qui arrive, selon Aditya Mukerjee « quand la fréquence ou la complexité des décisions est telle que la personne concernée évite de prendre une décision ou commet plus fréquemment des erreurs. »

Source: Aditya Mukerjee, Monitorama 2018 « Warning: This Talk Contains Content Known to the State of California to Reduce Alert Fatigue »
Prenons un exemple que Aditya a donné lors de son intervention :

Source: Aditya Mukerjee, Monitorama 2018 « Warning: This Talk Contains Content Known to the State of California to Reduce Alert Fatigue »
Dans un hôtel Disneyland, une pancarte indique que : « Le Complexe Disneyland renferme des produits chimiques réputés par l’État de Californie comme pouvant être à l’origine de cancers et de malformations congénitales ou d’autres pathologies du système reproductif. »
Cette pancarte ne fournit aucun contexte pour aider les visiteurs à prendre la bonne décision et adopter la ligne de conduite la plus appropriée. Imaginez la scène : des parents lisent cette pancarte et s’enfuient de l’hôtel sans même demander le remboursement de leurs dépenses en traînant leurs enfants hurlant derrière eux. Vous avez une assez bonne illustration de ce qui se passe quand vous combinez urgence de prendre une décision avec information sortie de son contexte (or cette information est censée vous aider à prendre la bonne décision…).
Aditya Mukerjee a fait référence, lors de sa conférence, à l’acronyme STAT longtemps utilisé par les services d’urgence pour définir les caractéristiques des alertes dignes d’intérêt pour les équipes :
- S comme “Supported” (Supporté) : toute personne qui est responsable de la supervision en lien avec l’alerte doit en connaître l’impact et être capable d’intervenir.
- T comme “Trustworthy” (Fiable): les alertes ne sont notifiées que s’il y a un problème, (jamais quand il ne se passe rien) et les personnes concernées ont assez d’information pour diagnostiquer le problème.
- A comme “Actionable” (Actionnable) : une alerte doit se traduire en acte et être interactive. La responsabilité du déclenchement de l’action doit être clairement définie.
- T comme “Triaged” (Trié et priorisé) : l’urgence et la priorité doivent être tangibles et être réévaluées si elles ne sont pas pertinentes.
Autre cousin germain de l’alerte fatigue et du surmenage décisionnel : le contexte !
3 – De l’importance du contexte (et du context automation)
Nous y voilà : les problématiques liées au contexte – tout comme notre travail et notre infrastructure IT – deviennent de plus en plus complexes. Bien qu’il puisse apparaître comme un concept un peu flou – qui peut être associé à l’intuition (« y’a comme un truc qui cloche ») – la question du contexte est surtout une capacité à mettre de l’ordre dans vos données afin de pouvoir les tracer, en une fraction de seconde, et ce, sans avoir à trop creuser. La plupart des personnes n’étant pas des « maniaques du rangement », la solution pour être organisé en matière de supervision informatique est d’utiliser l’automatisation de contexte (ou context automation). Lors de sa conférence, Andy Domeier a fourni un bon point de départ pour améliorer vos pratiques sur ce sujet.
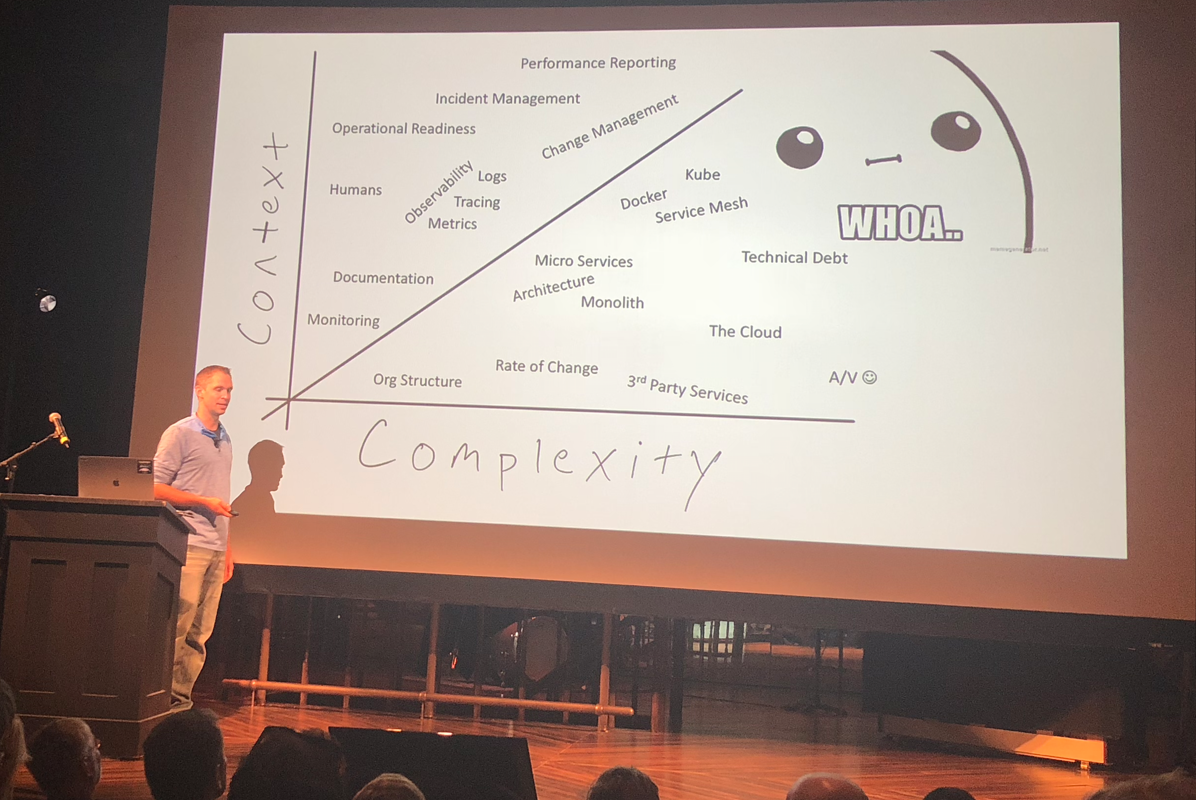
Source : Andy Domeier, Monitorama, Portland 2018, « Automate your Context »
Poursuivons le parallèle avec le rangement domestique : à chaque fois que vous avez une irrésistible envie d’hamburger, nous pouvons supposer que vous n’avez pas vraiment envie d’être obligé de fouiller le fin fond de votre réfrigérateur pour trouver de quoi cuisiner votre plat. Vous préférez trouver tous les ingrédients nécessaires, bien alignés et apparent, rangés sur l’étagère du réfrigérateur et attendant patiemment d’être utilisés pour votre prochaine fringale de hamburger.
Peut-être n’en n’avons-nous pas encore conscience, mais finalement, le travail de supervision s’apparente un peu à la préparation de hamburgers, dans une cuisine qui prendrait des commandes de personnes un peu difficiles et venues du monde entier. Les données doivent être regroupées par concepts et facilement visualisées (et analysées) dans un contexte donné. Parce que tout cela peut devenir désordonné, des outils avancés vous permettent de travailler avec des couches multiples de visualisation, comme Vizceral, par exemple, une solution née chez Netflix et qui est encore utilisée aujourd’hui pour comprendre l’état de leur architecture (complexe) de microservices, n’importe où dans le monde, en un coup d’œil, quand un problème réseau survient.
4 – L’observabilité
Nous avons particulièrement apprécié la présentation de Yan Cui au cours de laquelle il a contribué à définir une vision commune (et qui peut être mise en œuvre) de ce que l’on entend précisément par « Observabilité ». Pour beaucoup, l’Observabilité est simplement le nouveau nom (plus marketing) de la supervision, un peu comme DevOps est venu remplacer le terme Ops. Or, la supervision consiste à donner un état de santé global d’un système alors que l’observabilité consiste à fournir des informations très détaillées sur le comportement du système (log, traces, etc.) afin d’en corriger les anomalies. Alors oui, bien sûr, l’observabilité reste de la supervision mais une supervision qui prend place dans un continuum d’étapes déployées pour rendre le système observable. Retrouvez dans cet article comment l’équipe Observatory Engineering de Twitter a décrit l’observabilité pour la première fois.

Source: Yan Cui, Monitorama 2018, Portland, « The present and future of Serverless observability »
Rendre des systèmes IT distribués et complexes observables renforce les capacités de diagnostic des pannes et la corrections des anomalies. Cela permet de savoir ce qui se passe « sous le capot », de fournir des alertes riches de contexte, de donner du sens à ce qui se passe ou va se passer et d’engranger de l’information intelligence grâce aux données analytiques.

Source: Yan Cui, Monitorama 2018, Portland, « The present and future of Serverless observability »
Pour en savoir plus sur l’observabilité et le monitoring, vous pouvez lire cet article.
Yan Cui a ensuite centré sa conférence sur son sujet principal : l’observabilité des architectures serverless.
Les systèmes serverless, comme par exemple AWS Lambda, pose de nouveaux problèmes en termes d’observabilité. Clairement, ce sont des environnements qui nous contraignent à acquérir de nouvelles pratiques et à développer ou apprendre à utiliser de nouveaux outils. Yan Cui a listé des problèmes auxquels vous allez être confrontés en matière de supervision si vous manipulez les concepts serverless :
- L’impossibilité d’installer des agents/daemons
- Pas de possibilité de lancer des tâches de fond
- Une plus grande concurrence des systèmes de télémesure
- Des invocations asynchrones
Découvrez ces articles de Yan Cui que nous avons beaucoup appréciés.
5 – Symptômes vs causes
Nous avons également beaucoup apprécié l’approche de la supervision qui place le focus sur l’expérience utilisateur et le SLO (objectif de niveaux de services) plutôt que sur les causes potentielles de la dégradation de service. Avec ce paradigme, les alertes sont basées sur ce que perçoit l’utilisateur, tel que décrit dans le Google SRE Book :
« Votre système de supervision doit répondre à deux questions : qu’est-ce qui est cassé et pourquoi ? La première question va fournir le symptôme, la seconde la cause (éventuellement intermédiaire). « Quoi » vs « pourquoi », voilà ce qui va faire toute la différence pour mettre en place un système de supervision performant qui émettra un maximum de signaux en faisant un minimum de bruit. »
Pourquoi se centrer sur le point de vue de l’utilisateur et les symptômes se révèle la meilleure stratégie de supervision ? Tout simplement parce que, avec la croissance exponentielle de nos systèmes, l’expérience utilisateur est le socle le plus stable et le plus adaptable sur lequel s’appuyer.
Les utilisateurs ne changent pas alors que votre système, toujours en évolution, nécessite que vous élaboriez toujours plus de règles pour garder le contrôle.
En définissant des SLO clairs et en les intégrant au cœur du système de supervision et d’alertes, vous serez alertés uniquement quand il y a un vrai risque pour l’expérience client, et non pas quand des choses sans importance ne fonctionnent plus. Se centrer sur les symptômes est également une bonne stratégie pour faire face au surmenage décisionnel et l’alerte fatigue.
Le 4 et 5 septembre 2018, nous serons à Amsterdam pour assister la prochaine édition du Monitorama et vous nous ferons un plaisir de vous tenir au courant des dernières tendances.
Envie de savoir comment Centreon peut vous aider sur les principaux enjeux de la supervision ? Contactez-nous.
Restez informé sur les dernières tendances qui font la supervision d’aujourd’hui.
Partager











